
Introduction
In a previous post, I wrote about running local LLMs using Ollama and briefly touched on how we can use the Ollama API to make programmatic calls to models running on Ollama. In this post, we’ll build our first application using Python and Ollama. If you are new to Ollama and local LLMs, I recommend reading that post before starting this one.
Ollama API
As discussed in the previous post, Ollama exposes an API on port 11434. To interact with a model running in Ollama, we send a POST request with a payload to http://localhost:11434/api/generate. If we send the request below:
import requests
# Define the local API endpoint
OLLAMA_URL = "http://localhost:11434/api/generate"
# Define the request payload
payload = {
"model": "llama3.2:3b-instruct-q4_K_M",
"prompt": "Explain the benefits of running AI models locally.",
"system": "You are an assistant who explains concepts clearly and concisely.",
"stream": False
}
# Make the POST request
response = requests.post(OLLAMA_URL, json=payload)
# Check response
if response.status_code == 200:
print("Response:", response.json()["response"])
else:
print("Error:", response.status_code, response.text)
We get a response like this
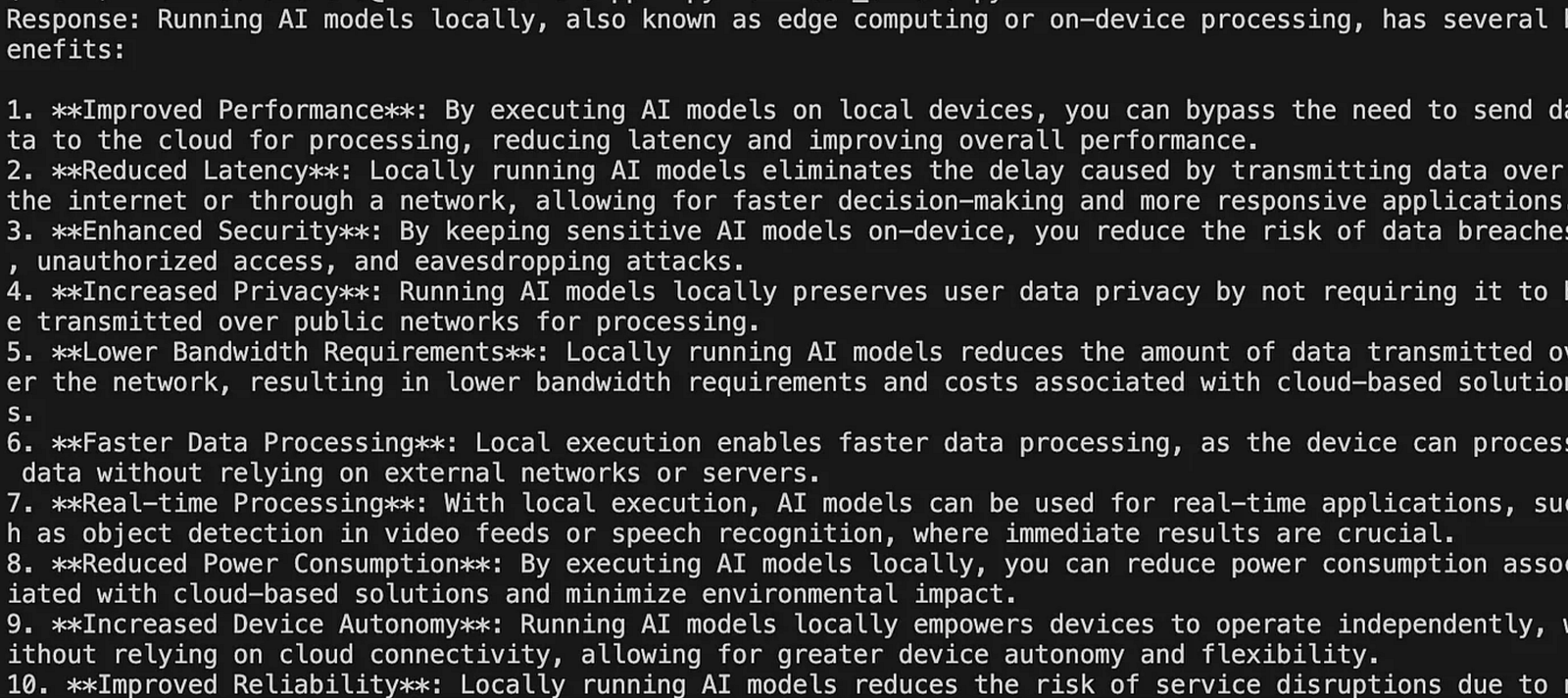
What are we going to build ?
We’ll build a Hacker News summarizer app, where each summary is generated using a local LLM (llama3.2:3b-instruct-q4_K_M). This model is relatively small (2GB), making it suitable for older hardware, with impressive inference speed. In my experiments, I’ve found it performs quite well at summarizing texts.
The idea behind this app is to summarize articles from Hacker News and store the summaries, along with the article URLs, in an Excel sheet. This allows users to quickly browse the Excel file and cherry-pick articles to read based on their interests.
Implementation
Tools
- Python 3.11
- Python IDE of your choice
- Ollama available on local machine: Refer to this article
- uv installed and working : Refer to this article
Prerequisites
Local model is running: To run the model, follow the instructions below:

Once the model is running, you can verify its availability using the command below:

Implementation Steps
Step 0: Init the project
uv init hackernewsapp
Step 1: Install dependencies
Install the below dependencies
[project]
name = "hackernewsapp"
version = "0.1.0"
description = "Add your description here"
readme = "README.md"
requires-python = ">=3.11"
dependencies = [
"beautifulsoup4>=4.12.3",
"openai>=1.54.4",
"openpyxl>=3.1.5",
"pandas>=2.2.3",
"python-dotenv>=1.0.1",
"requests>=2.32.3",
"schedule>=1.2.2",
]
Step 2: Create a file app.py and put the below code in :
import os
import schedule
import time
from datetime import datetime
from dotenv import load_dotenv
from hn_fetcher import fetch_top_stories
from article_summarizer import summarize_articles
from database import init_db, save_articles
load_dotenv()
def main():
print("HackerNews Summary App Started!")
# Delete existing database if it exists
if os.path.exists('hackernews.db'):
print("Removing old database...")
os.remove('hackernews.db')
# Initialize the database
init_db()
def fetch_and_summarize():
print(f"\nFetching articles at {datetime.now()}")
articles = fetch_top_stories(limit=10) # Get top 10 stories
articles_with_summaries = summarize_articles(articles)
save_articles(articles_with_summaries)
print("Articles fetched, summarized and saved!")
# Print the latest articles
for article in articles_with_summaries:
print(f"\nTitle: {article['title']}")
print(f"URL: {article['url']}")
print(f"Summary: {article['summary']}")
print("-" * 50)
# Schedule the job to run daily at 9 AM
schedule.every().day.at("09:00").do(fetch_and_summarize)
# Run once immediately when starting
fetch_and_summarize()
# Keep the script running
while True:
schedule.run_pending()
time.sleep(60)
if __name__ == "__main__":
main()
This code serves as the entry point to the application. It calls fetch_top_stories from hn_fetcher.py, followed by summarize_articles from article_summarizer.py.
Step 3: Put the following code in hn_fetcher.py
import requests
from typing import List, Dict
import time
from bs4 import BeautifulSoup
from urllib.parse import urlparse
def get_article_content(url: str) -> str:
"""Fetch and extract text content from article URL"""
try:
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'}
response = requests.get(url, headers=headers, timeout=10)
soup = BeautifulSoup(response.text, 'html.parser')
# Remove script and style elements
for script in soup(["script", "style"]):
script.decompose()
# Get text content
text = soup.get_text(separator='\n', strip=True)
# Clean up text: remove extra newlines and spaces
lines = (line.strip() for line in text.splitlines())
text = ' '.join(line for line in lines if line)
# Limit text length to avoid overwhelming the model
return text[:8000] # Limit to first 8000 characters
except Exception as e:
print(f" Error fetching article content: {str(e)}")
return ""
def fetch_top_stories(limit: int = 10) -> List[Dict]:
"""Fetch top stories from Hacker News API"""
print("\n=== Fetching Stories from Hacker News ===")
# Get top story IDs
response = requests.get("https://hacker-news.firebaseio.com/v0/topstories.json")
story_ids = response.json()[:limit]
articles = []
for i, story_id in enumerate(story_ids, 1):
# Get story details
story_url = f"https://hacker-news.firebaseio.com/v0/item/{story_id}.json"
story = requests.get(story_url).json()
# Only include stories with URLs
if 'url' in story:
print(f"\n{i}. Story Found:")
print(f" Title: {story.get('title')}")
print(f" URL: {story.get('url')}")
print(f" Score: {story.get('score')}")
print(" Fetching article content...")
content = get_article_content(story.get('url'))
article = {
'title': story.get('title'),
'url': story.get('url'),
'score': story.get('score'),
'timestamp': story.get('time'),
'content': content
}
articles.append(article)
# Be nice to the API
time.sleep(0.1)
return articles
This file retrieves the top stories from Hacker News and fetches the content for each one. In addition to the text content, it also gathers the title, URL, score, and timestamp for each story.
Step 4: Next steps is the save the articles, where articles are saved in the sqlite db and then pushed to the excel file, and these functions live in database.py. There is a lot of boilerplate code, so I’ll just post the relevant snippets below, check the github link to get the full code
The next step is to save the articles. The articles are stored in an SQLite database and then exported to an Excel file. These functions are located in database.py. Since there is a lot of boilerplate code, I’ll share only the relevant snippets below. Check the Github Link for the full code.
def save_articles(articles: List[Dict]):
"""Save articles to the database"""
conn = sqlite3.connect('hackernews.db')
c = conn.cursor()
for article in articles:
c.execute('''
INSERT INTO articles
(title, url, summary, score, timestamp, content, fetched_at)
VALUES (?, ?, ?, ?, ?, ?, ?)
''', (
article['title'],def save_articles(articles: List[Dict]):
"""Save articles to the database"""
conn = sqlite3.connect('hackernews.db')
c = conn.cursor()
for article in articles:
c.execute('''
INSERT INTO articles
(title, url, summary, score, timestamp, content, fetched_at)
VALUES (?, ?, ?, ?, ?, ?, ?)
''', (
article['title'],
article['url'],
article['summary'],
article['score'],
article['timestamp'],
article.get('content', ''),
datetime.now().isoformat()
))
conn.commit()
conn.close()
# After saving to database, create Excel export
export_to_excel(articles)
def export_to_excel(articles: List[Dict]):
"""Export articles to Excel file"""
# Create a directory for exports if it doesn't exist
os.makedirs('exports', exist_ok=True)
# Use a fixed filename instead of timestamp-based
filename = 'exports/hackernews_summaries.xlsx'
# Format the data for new articles
new_data = []
for article in articles:
new_data.append({
'Date': datetime.now().strftime('%Y-%m-%d %H:%M:%S'),
'Title': article['title'],
'URL': article['url'],
'Summary': article['summary'],
'Score': article['score']
})
new_df = pd.DataFrame(new_data)
if os.path.exists(filename):
# Read existing Excel file
existing_df = pd.read_excel(filename)
# Concatenate existing data with new data
df = pd.concat([existing_df, new_df], ignore_index=True)
print(f"\nAppending {len(new_data)} articles to existing Excel file: {filename}")
else:
df = new_df
print(f"\nCreating new Excel file: {filename}")
# Export to Excel with formatting
with pd.ExcelWriter(filename, engine='openpyxl') as writer:
df.to_excel(writer, index=False, sheet_name='Summaries')
# Auto-adjust column widths
worksheet = writer.sheets['Summaries']
for idx, col in enumerate(df.columns):
max_length = max(
df[col].astype(str).apply(len).max(),
len(col)
)
worksheet.column_dimensions[chr(65 + idx)].width = min(max_length + 2, 100)
print(f"Excel file saved with {len(df)} total articles") article['url'],
article['summary'],
article['score'],
article['timestamp'],
article.get('content', ''),
datetime.now().isoformat()
))
conn.commit()
conn.close()
# After saving to database, create Excel export
export_to_excel(articles)
def export_to_excel(articles: List[Dict]):
"""Export articles to Excel file"""
# Create a directory for exports if it doesn't exist
os.makedirs('exports', exist_ok=True)
# Use a fixed filename instead of timestamp-based
filename = 'exports/hackernews_summaries.xlsx'
# Format the data for new articles
new_data = []
for article in articles:
new_data.append({
'Date': datetime.now().strftime('%Y-%m-%d %H:%M:%S'),
'Title': article['title'],
'URL': article['url'],
'Summary': article['summary'],
'Score': article['score']
})
new_df = pd.DataFrame(new_data)
if os.path.exists(filename):
# Read existing Excel file
existing_df = pd.read_excel(filename)
# Concatenate existing data with new data
df = pd.concat([existing_df, new_df], ignore_index=True)
print(f"\nAppending {len(new_data)} articles to existing Excel file: {filename}")
else:
df = new_df
print(f"\nCreating new Excel file: {filename}")
# Export to Excel with formatting
with pd.ExcelWriter(filename, engine='openpyxl') as writer:
df.to_excel(writer, index=False, sheet_name='Summaries')
# Auto-adjust column widths
worksheet = writer.sheets['Summaries']
for idx, col in enumerate(df.columns):
max_length = max(
df[col].astype(str).apply(len).max(),
len(col)
)
worksheet.column_dimensions[chr(65 + idx)].width = min(max_length + 2, 100)
print(f"Excel file saved with {len(df)} total articles")
Final Step: Once all the files are in place, you can run the project using the command below:
uv run app.py
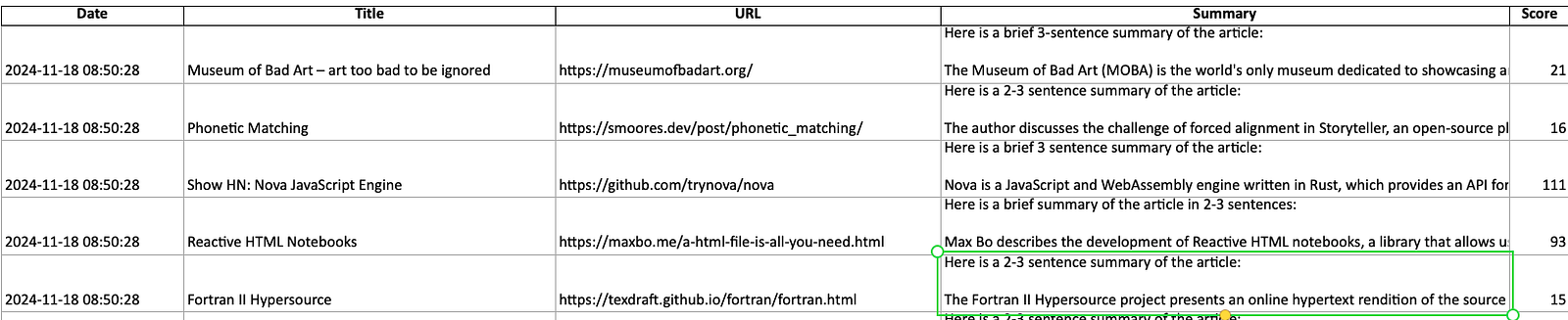
On successful execution, we can see the excel sheet with all the urls and summary in the export folder
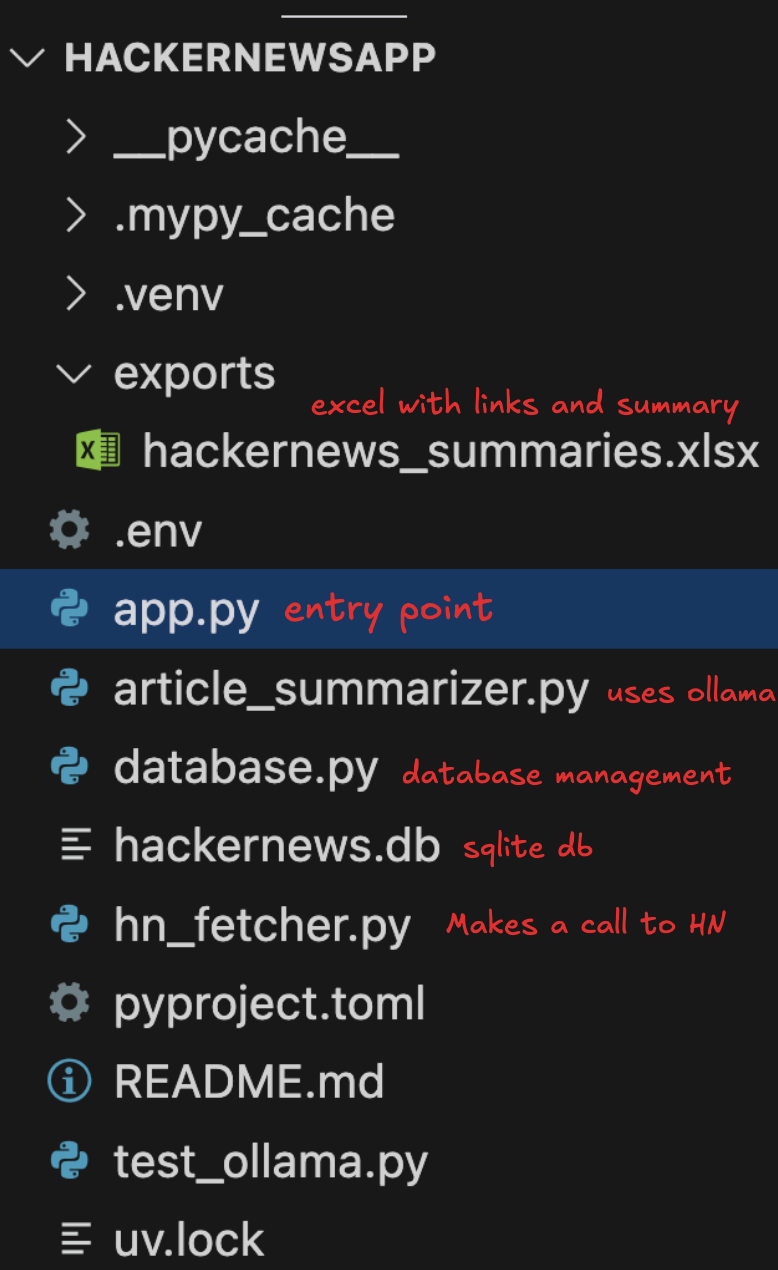
Final Project Structure
After all the files project structure would look like below :
Conclusion
Running LLMs locally with tools like Ollama offers unmatched benefits — enhanced data privacy, no recurring costs, and offline functionality. In this post, we showcased how to build a simple app using the Ollama API for tasks like summarization, demonstrating its ease of use and effectiveness for straightforward use cases.
Local models are perfect for exploring creative applications, automating tasks, or working with sensitive data. With their growing capabilities, now is the perfect time to experiment and unlock new possibilities in AI-driven development. I’d love to hear what you plan to build — feel free to share your ideas and projects!
Resources
GitHub Repository: HackerNewsApp
UV Documentation: Getting Started with Installation
🌟 Stay Connected! 🌟
I love sharing ideas and stories here, but the conversation doesn’t have to end when the last paragraph does. Let’s keep it going!
🔹Website : https://madhavarora.net
🔹 LinkedIn for professional insights and networking: https://www.linkedin.com/in/madhav-arora-0730a718/
🔹 Twitter for daily thoughts and interactions:https://twitter.com/MadhavAror
🔹 YouTube for engaging videos and deeper dives into topics: https://www.youtube.com/@aidiscoverylab
Got questions or want to say hello? Feel free to reach out to me at madhavarorabusiness@gmail.com. I’m always open to discussions, opportunities, or just a friendly chat. Let’s make the digital world a little more connected!